Importante saber que al menos una base de datos activa o mejor dicho que esta corriendo, debe de tener una instancia asociada. De la misma manera, como la instancia existe en memoria y la base de datos existe en disco, una instancia puede existir sin una base de datos y una base de datos puede existir sin una instancia, si no me crees esto, haz la prueba, arranca la instancia en modo nomount y veras que sin existir los datafiles,controlfiles y redo logs puedes iniciar la instancia
TESTDB >startup nomount ORACLE instance started. Total System Global Area 1369989120 bytes Fixed Size 2158184 bytes Variable Size 268439960 bytes Database Buffers 1090519040 bytes Redo Buffers 8871936 bytes oracle@localhost [TESTDB] /mount/dba01/oracle/TESTDB/admin oracle $ ps -eaf | grep TESTDB oracle 27411 1 0 01:21:35 ? 0:00 ora_pmon_TESTDB oracle 27448 1 0 01:21:37 ? 0:00 ora_ckpt_TESTDB oracle 27435 1 0 01:21:37 ? 0:00 ora_dia0_TESTDB oracle 27439 1 0 01:21:37 ? 0:00 ora_dbw0_TESTDB oracle 27454 1 0 01:21:37 ? 0:00 ora_mmon_TESTDB oracle 27415 1 0 01:21:35 ? 0:00 ora_psp0_TESTDB oracle 27444 1 0 01:21:37 ? 0:00 ora_dbw1_TESTDB oracle 27431 1 0 01:21:37 ? 0:00 ora_diag_TESTDB oracle 27446 1 0 01:21:37 ? 0:00 ora_lgwr_TESTDB oracle 27452 1 0 01:21:37 ? 0:00 ora_reco_TESTDB oracle 27450 1 0 01:21:37 ? 0:00 ora_smon_TESTDB
Aqui abajo esta una pequeña grafica de como se conforma una instancia:
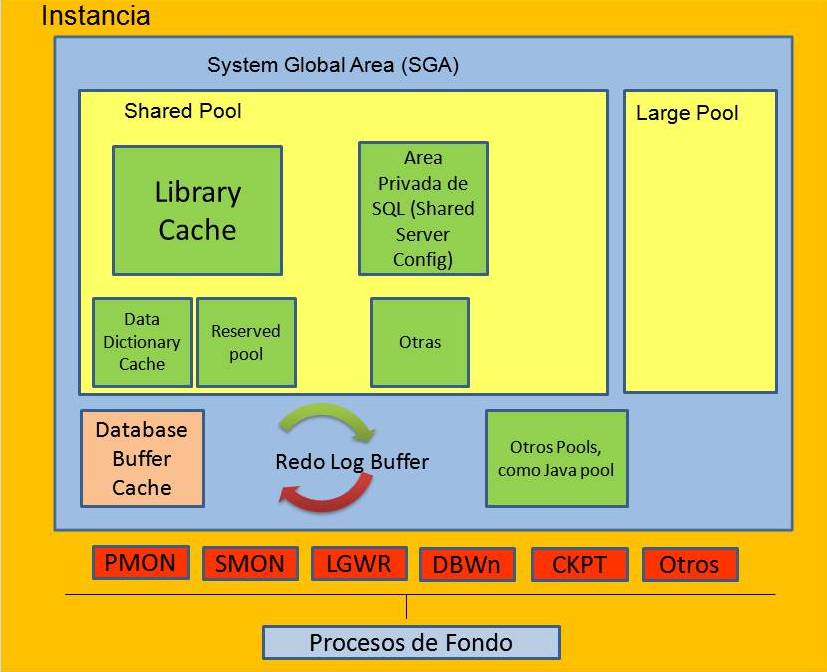
Y debido a lo que platicamos arriba, es lo que permite la configuracion para RAC (Real Application Cluster), asi tambien es importante saber que una instancia no puede tener asociada una sola base de datos a la vez, o sea que no puedes montar dos base de datos en una instancia.

La memoria SGA tiene 3 estructuras básicas:
Database buffer cache.- Es el área de memoria que almacena copias de los bloques de datos leídos de los data files.Tambien a esta área se le conoce nada mas como Buffer Cache. Esta seccion de la memoria tiene tres estados.
- Sin Usar (Unused).-El buffer esta disponible por que nunca se ha usado o actualmente esta sin usar.
- Limpia (Clean).-Este buffer fue usado previamente, y ahora contiene una version consistente del bloque de datos en un punto en tiempo. El bloque contiene datos, pero este se puede decir que esta limpio, ya que no se le necesita hacer un checkpoint a los datos.
- Sucia (Dirty).-El buffer contiene datos que no han sido escrito a disco, Oracle necesita hacer un checkpoint del bloque de datos antes de reusarlo. Para manejar estos estados, Oracle tiene un algortimo llamado LRU (Least Recently Used), lo que hace este algoritmo es sacar del buffer a los bloques de datos menos usados y que ya se le hayan hecho un checkpoint para asi poder subir al Buffer Cache nuevos datos y evitar sacar del Buffer Cache los datos que se usan con frecuencia.
Shared Pool .- Esta área de memoria guarda SQL analizado (Parsed),parámetros del sistema y el diccionario de datos (Data Dictionary Cache y Library Cache).
Redo Log Buffer.- Esta estructura de memoria en el SGA, que guarda los registros de Redo, estos contienen la información necesaria para reconstruir los cambios hechos por DDLs o DMLs a la base de datos.
Procesos
Existen varios que son obligatorios, como los mencionados aqui abajo, de la misma manera existen muchos procesos que se inician una vez que añades alguna funcionalidad, como el ARCn, que es cuando la base de datos esta en modo archivelog.
PMON.- La funcionalidad de este proceso es la de monitorear que los demás procesos de la instancia estén corriendo, a su vez es responsable de limpiar el Database Buffer Cache y limpiar recursos que el cliente haya utilizado.
SMON.-La tarea principal de este proceso es la de limpieza a nivel sistema, y también una de las tareas principales de este proceso es llevar a cabo la recuperación al iniciar la instancia cuando anteriormente finzalizo de una manera abrupta, como un shutdown abort o un crash del servidor.
CKPT.-Su función es la de actualizar las cabeceras de los control files y de los data files, con información de Checkpoint (SCN, Posición de Checkpoint, etc), a su vez la avisa al DBWn que debe de escribir los bloques del Buffer Cache a disco. Muy importante saber, que el CKPT no escribe los datos, ni al Redo Log ni a los data files.
DBWn.-Este proceso escribe los contenidos sucios del buffer Cache, a este proceso se le conoce como un proceso flojo, ya que por si solo no escribe a disco, este unicamente escribe a disco cuando no hay bloques de datos limpios en el buffer cache o cuando CKPT le informa que debe hacerlo.
LGWR.- De lo que se encarga es de escribir los Redo Log Buffers a disco (Online Redo Log). Este proceso utiliza un método que se le conoce como Fast Commit. Cuando un usuario ejecuta un commit, a la transacción se le asigna un SCN (System Change Number), LGWR pone una marca de commit en el Buffer Cache e inmediatamente escribe a disco, cuando se han escrito estos datos en el Online Redo Log, el proceso actualiza el Buffer Cache haciendo mención de que estos ya se escribieron a disco.
Conclusion
Espero que esta pequeña explicación te ayude a comprender la diferencia entre la Instancia y lo que en Oracle se conoce como Base de Datos. De la misma manera los procesos basicos y memoria basica de la instancia, para los procesos y la memoria existen mas de los mencionados aqui, pero estos son los minimos necesarios en una configuracion de Oracle.